by Nick
Posted on 23 November, 2016
For the second year in a row, the Reich Lab is participating in the CDC FluSight challenge, a project where teams from around the country submit real-time predictions of influenza to the CDC. The teams use a variety of different models and methods to generate these predictions, from an empirical Bayes method that uses Google search data to a extended Kalman-filter method that uses humidity data to our kernel conditional density estimation method using recent incidence, and there are many others!
This year, we – well, mostly Evan – have developed a new ensemble method that combines predictions from different models. We – mostly Abhinav – also created a visualizer for our predictions. Check it out here! It’s still early in the season, and we’re not seeing much data to suggest that this will be an unusually high or low year, but that’s largely because there just isn’t much information in the early-season data. In this post, I’m going to give you a quick tour under the hood of our ensemble forecasting methodology. At some point, we’ll have an article up on GitHub or arXiv, but for now, this explanation will have to suffice.
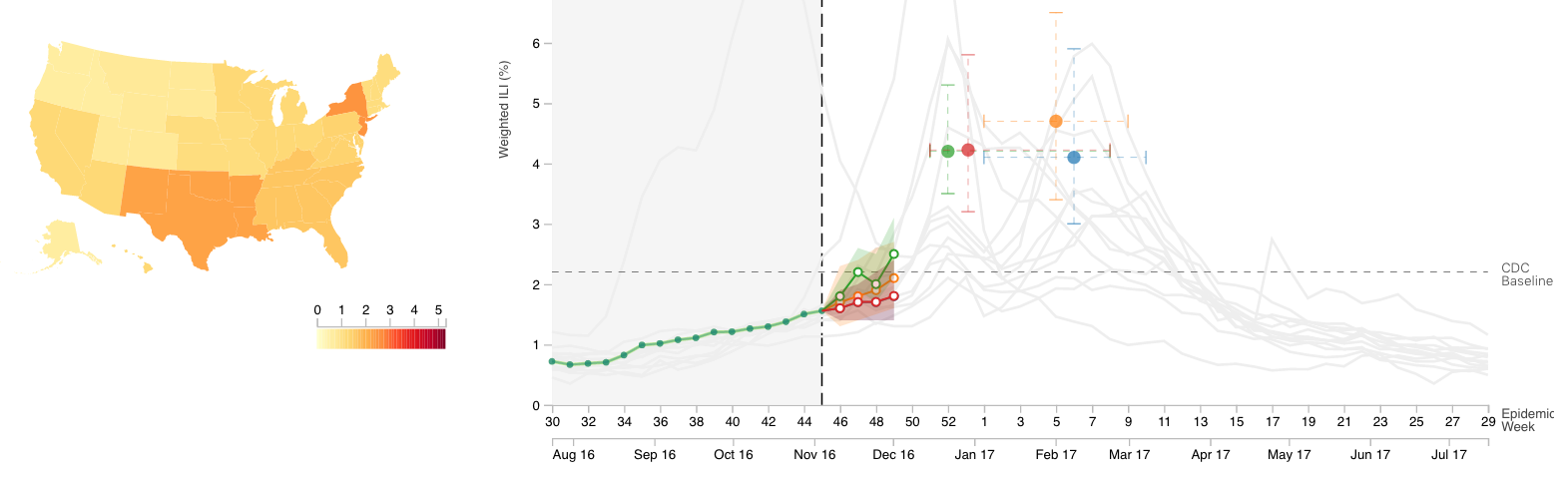
We call our team the Kernel of Truth (left over from our KCDE methods last year, although we hope the name still is appropriate). The contest is based on predicting a measure of influenza incidence that represents the percentage of all doctor’s visits that are for influenza-like-illness (ILI), weighted by population. The measure is called “weighted ILI” and its units are percentage points. Per contest rules, all submissions have to submit full predictive distributions each week from November through April for seven different targets of interest, for each of the HHS regions in the U.S. (and for the country as a whole). Here are the targets
For our submissions this year, we obtain the final predictive distributions as a weighted average of predictions from three component models:
The final predictions are obtained as a linear combination of the predictions from these component models using a method known as “stacking” or model averaging. The model weights depend on the week of the season in which the predictions are made. There is a lot of gnarly math and computation that we’re leaving out here, but if you’d like to see it let us know in the comments section and post some more details. We estimate the weights via gradient tree boosting, optimizing leave-one-season-out crossvalidated log scores (using the definition of log scores specified for this competition). Currently we are using the xgboost package in R to implement this, although there have been some rumblings about moving to another method, as this one is giving us some problems when the curvature of our loss function is negative. I’ll spare you the details for now.
We are submitting two variations on the ensemble model:
There is a lot more work to do on this to get it to where we want to it be, but one of the “advantages” of these challenges is that they force you to get stuff out there and just try it out. Some of the things that we are thinking about doing are improving the estimation methodology for the weights (including perhaps some kind of smoothing or regularization of the weights), adding a more mechanistic model that incorporates some biological features of flu, and incorporating the uncertainty in recent observations (as you can see in the app, there can be adjustments to reported cases, especially in the most recently reported weeks). So, there’s lots to do, and we’re hopefully just getting started.