MacArthur I, Robacker T, Case B, Fox SJ, Morris DH, Ray EL, Rogers B, Sweger B, Linton NM, Huddleston JL, Magee A, Susswein Z, Lee J, Bedford T, Figgins MD, Suez E, Prabhakar R, Leon T, Siegel B, Thakur M, Hoover CM, Ryder R, Elder J, Kupperman M, Ke R, Goldberg E, Funk S, Griffin M, Reich NG, Johnson KE (2026). arXiv.
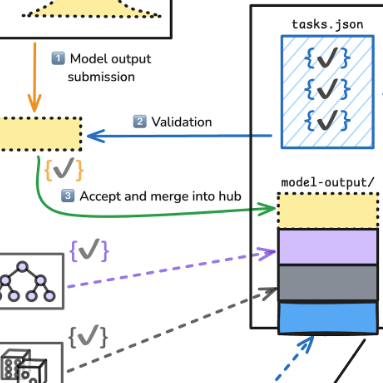
Shandross L, Howerton E, Contamin L, Hochheiser H, Krystalli A, Consortium of Infectious Disease Modeling Hubs, Reich NG, Ray EL (2026). Statistics in Medicine, 45(1-2): e70333.
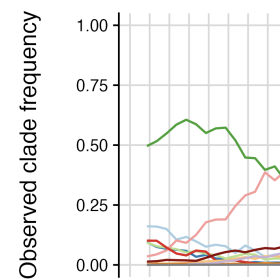
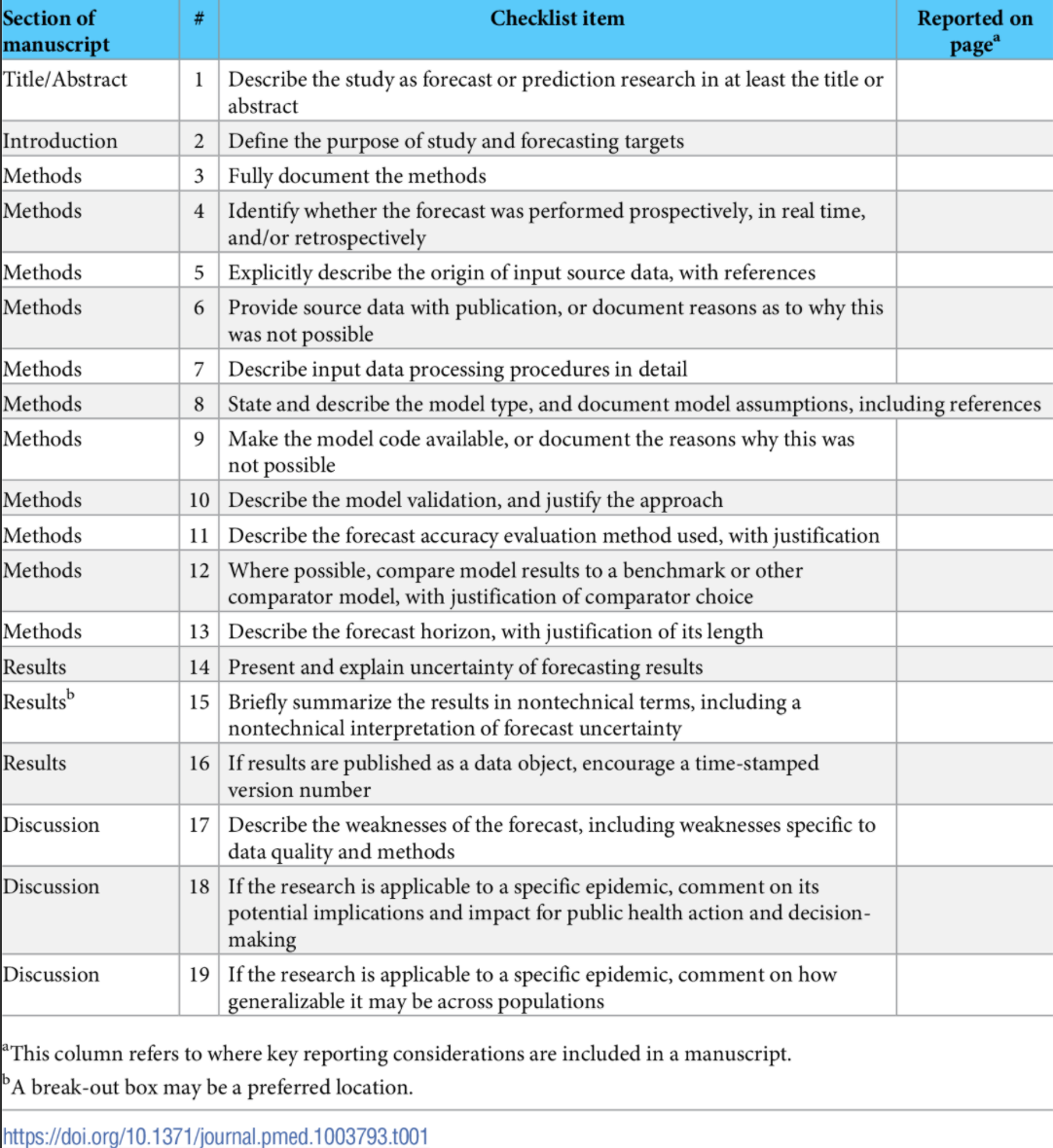
Johnson KE, Tang ML, Tyszka E, Jones L, Nemcova B, Wolffram D, Ergas R, Reich NG, Funk S, Mellor J, Bracher J, Abbott S (2025). Wellcome Open Research, 10: 614.
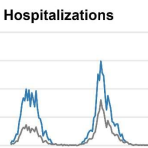
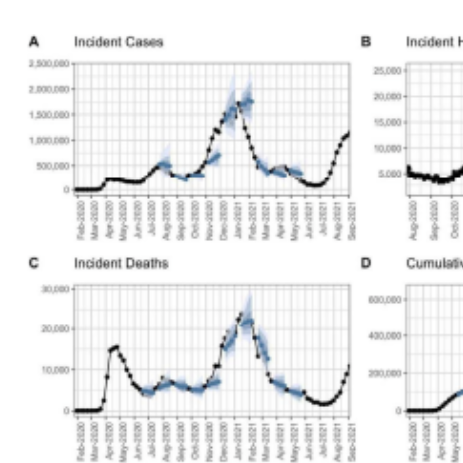
Mathis SM, Webber AE, ... Cramer EY, Gerding A, Stark A, Ray EL, Reich NG, Shandross L, Wattanachit N, Wang Y, Zorn MW, , ... Reed C, Biggerstaff M, Borchering RK (2025). Nature Communications, 15(1): 6289.
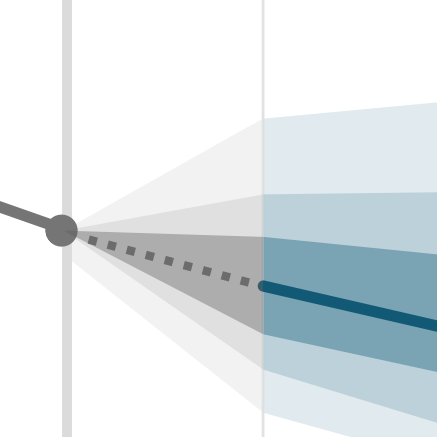
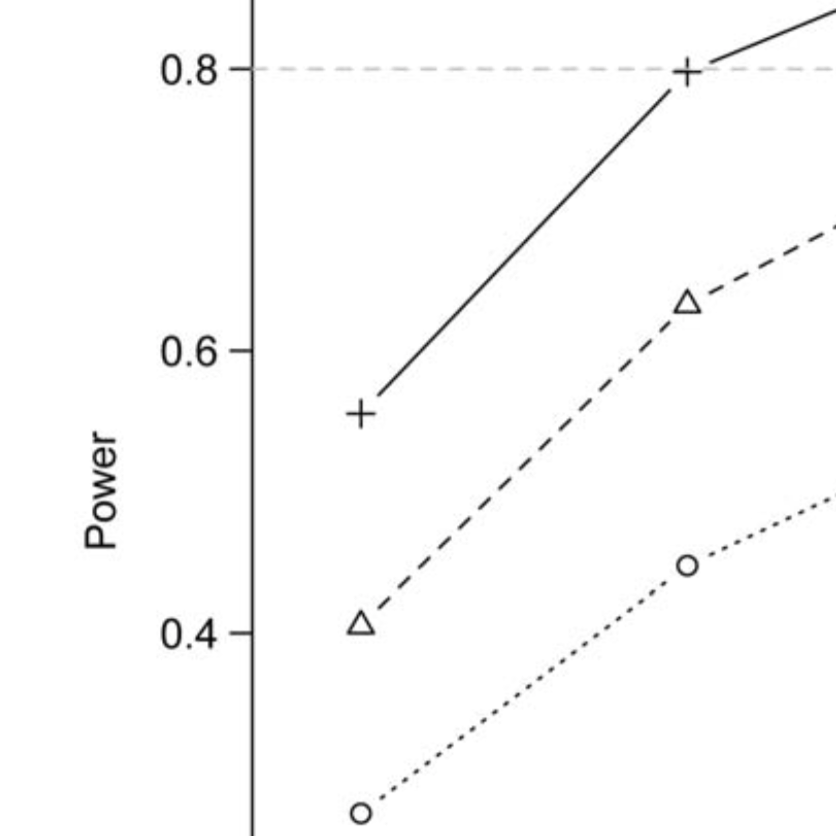
Ray EL, Brooks LC, Bien J, Biggerstaff M, Bosse NI, Bracher J, Cramer EY, Funk S, Gerding A, Johansson MA, Rumack A, Wang Y, Zorn M, Tibshirani RJ, Reich NG (2022). International Journal of Forecasting, 39: 1366-1383.
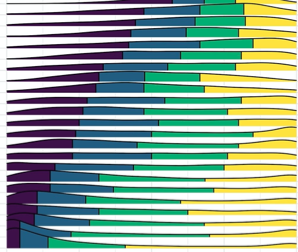
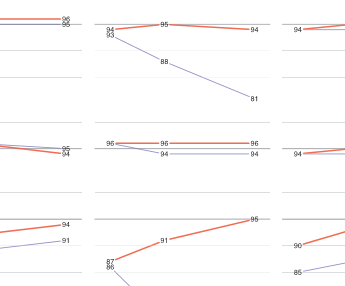
Cramer EY, Huang Y, Wang Y, Ray EL, Cornell M, Bracher J, Brennen A, Castro Rivadeneira AJ, Gerding A, House K, Jayawardena D, Kanji AH, Khandelwal A, Le K, Niemi J, Stark A, Shah A, Wattanachit N, Zorn MW, Reich NG (2022). Scientific Data, 9(1): 1-15.
Hossain FA, Lover AA, Corey GA, Reich NG, Rahman T (2020). Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 4(1): 1.
George GB, Taylor W, Shaman J, Rivers C, Paul B, O'Toole T, Johansson MA, Hirschman L, Biggerstaff M, Asher J, Reich NG (2019). Nature Communications, 10(3932).
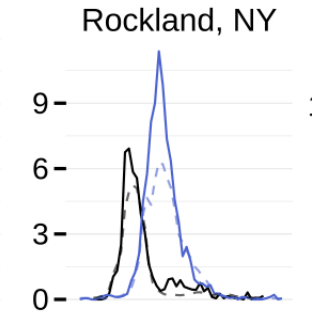
Reich NG, Brooks L, Spencer F, Kandula S, McGowan C, Moore E, Osthus D, Ray E, Tushar A, Yamana T, Biggerstaff M, Johansson MA, Rosenfeld R, Shaman J (2019). PNAS, 116(8): 3146-3154.
McGowan C, Biggerstaff M, Johansson M, Apfeldorf K, Ben-Nun M, Brooks L, Convertino M, Erraguntla M, Farrow D, Freeze J, Ghosh S, Hyun S, Kandula S, Lega J, Liu Y, Michaud N, Morita H, Niemi J, Ramakrishnan N, Ray EL, Reich NG, Riley P, Shaman J, Tibshirani R, Vespignani A, Zhang Q, Reed C (2019). Scientific Reports, 9(683).
Lauer SA, Sakrejda K, Ray EL, Keegan LT, Bi Q, Suangtho P, Hinjoy S, Iamsirithaworn S, Suthachana S, Laosiritaworn Y, Cummings DAT, Lessler J and Reich NG (2018). PNAS, 115(10): E2175-E2182.
Lessler J, Ott CT, Carcelen AC, Konikoff JM, Williamson J, Bi Q, Reich NG, Cummings DAT, Kucirka LM, Chaisson LH (2016). Bulletin of the World Health Organization, 94.